
Caravan Customer Identification Study - Deep Learning Approach
- Tommy Lam

- Jul 2, 2020
- 6 min read
Updated: Jul 20, 2020
Customer identification, one of the most common applications of machine learning in the business area, aims to identify potential customers. This would enhance the effectiveness of marketing campaigns, prevent the waste of resources on focusing on the wrong target group.
In the previous part of this project, I have performed exploratory data analysis (EDA) on the dataset to have a big picture on the dataset and see how is the target group (caravan users) looks like. After the EDA, I have performed some basic machine learning over the dataset (logistic regression, KNN classification and random forest). The project can be viewed here.
In this project, I will demonstrate a higher level of classification on the caravan customer prediction with deep learning techniques.
Objective
The goal of this project is to predict the potential user of caravan based on sociodemographic and product usage attributes.
Previous result
In the previous section, I have used several machine learning algorithms - logistic regression, random forest and KNN classification. They did not give a robust result unfortunately hence I will explore this topic with a deep learning approach.
Difficulties
Our target users, the caravan users, are the minority among the population, i.e. only 6% of people are the caravan users in this dataset.
This is a typical imbalanced classification problem similar to fraud detection, spam filtering, subscription churn where the target group is the minority. It is hard to find them out since the predictions generally give negative results to achieve high accuracy.
There are several ways to handle the imbalanced classification:
Scale up the minority group
Scale down the majority group
Use a penalizing model (such as SVC)
Use a tree-based algorithm (Decision Tree, Random Forest)
In this project, I will scale up the minority group such that the ratio of caravan customer would be 1:1. After that, I will build a neural network model to determine whether if a person is potentially a caravan user, based on sociodemographic and product usage attributes.
Let's start now!
Import libraries
First of all, we need to import the libraries that required in this project. These are all the libraries we may need in this project.
# Basic data manipulation
import pandas as pd
import numpy as np
# Data visualisation
import matplotlib.pyplot as plt
import seaborn as sns
# Data processing
from sklearn.utils import resample
from sklearn.model_selection import train_test_split
# Deep learning setup
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.utils import plot_model
# Model evaluation
from sklearn.metrics import plot_confusion_matrix
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_reportDataset
The dataset includes two main components. The first one is whether the user is a caravan user. This would be our target variable in this project. The second part consists of 85 attributes, containing sociodemographic data and product ownership information.
Here are 3 data files we used in this project.
TICDATA2000.txt: Dataset to train and validate prediction models and build a description (5822 customer records). Each record consists of 86 attributes, containing sociodemographic data (attribute 1-43) and product ownership (attributes 44-86). The sociodemographic data is derived from zip codes. All customers living in areas with the same zip code have the same sociodemographic attributes. Attribute 86, "CARAVAN: Number of mobile home policies", is the target variable.
TICEVAL2000.txt: Dataset for predictions (4000 customer records). It has the same format as TICDATA2000.txt, only the target is missing. Participants are supposed to return the list of predicted targets only. All datasets are in tab-delimited format. The meaning of the attributes and attribute values is given below.
TICTGTS2000.txt Targets for the evaluation set.
The data dictionary, also called a Data Definition Matrix, provides detailed information about the business data. It is included in the following link: Data dictionary: https://kdd.ics.uci.edu/databases/tic/dictionary.txt
train_data = pd.read_csv('data/ticdata2000.txt',header=None, delim_whitespace= True)
predict_data = pd.read_csv('data/ticeval2000.txt',header=None, delim_whitespace= True)
target_data = pd.read_csv('data/tictgts2000.txt',header=None, delim_whitespace= True)Data Wrangling
Before we proceed to the model, we need to wrangle the data structure to optimise the model performance. Some of the data are represented by coding, for example, the age-group is presented as 1 to 6. Since these variables are continuous and their values would be meaningful in the models, they are converted into mean values of each group.
train_data[['V4','V6','V42']].head()
Resampling
When we look at the distribution of the target data, i.e. Caravan user, we can observe the huge gap between users and non-users. It is a typical imbalanced classification problem that the target group is uncommon (0-10% of the total population), such as error detection, customer churning prediction, etc.
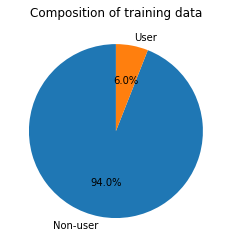
If we run the models directly over the imbalanced data, the results would be negative in general to achieve high accuracy. Therefore, we need to restructure our database. The minority group, the caravan users, would be scaled up by resampling such that the ratio of users to non-users will be even.
Therefore, I will upscale the minority group in the following steps such that the ratio of caravan users and non-users will be 1:1.
# Separate majority and minority classes
df_majority = train_data[train_data.V86==0]
df_minority = train_data[train_data.V86==1]
# Upsample minority class
df_minority_upsampled = resample(df_minority,
replace=True, # sample with replacement
n_samples=5474) # to match majority class
# Combine majority class with upsampled minority class
df_upsampled = pd.concat([df_majority, df_minority_upsampled])
# Display new class counts
df_upsampled.V86.value_counts()
-------------------------------------------------------
1 5474
0 5474
Name: V86, dtype: int64So now the ratio of the user to non-user is even. The data are ready for further processing. The training dataset will be randomly split into training and validation set.
x_train, x_test, y_train, y_test = train_test_split(
df_upsampled.iloc[:,0:85], df_upsampled.iloc[:,85:86], test_size=0.3)
--------------------------------------------------------
x_train shape: (7663, 85)
x_test shape: (3285, 85)
y_train shape: (7663, 1)
y_test shape: (3285, 1)The next step will be the implementation of deep learning model on the training and validation set.
Data Modelling
Model Setup
In this section, I will build a neural network model with 3 hidden layers with Keras. Keras is a python library that can provide a simple way to construct deep learning models. We will use the training set to train the model and use the validation set to make sure the model is trained in the right direction. The ratio of the training set to testing set is 7:3.
model = Sequential()
model.add(Dense(32, input_dim=85, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])Model Structure
The following graph shows the structure of the neural network model with 3 hidden layers.
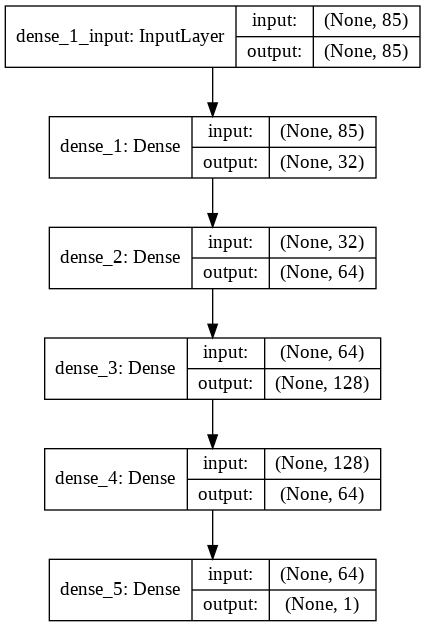
Model Training
Let's train the model. The model took around 50 epochs to converge to the optimum result and the whole training process took only 30 seconds!
Train...
Train on 7663 samples, validate on 3285 samples
Epoch 1/50 7663/7663 [==============================] - 1s 78us/step - loss: 0.6414 - accuracy: 0.6490 - val_loss: 0.5984 - val_accuracy: 0.6709
...
Epoch 50/50 7663/7663 [==============================] - 0s 57us/step - loss: 0.0731 - accuracy: 0.9765 - val_loss: 0.1509 - val_accuracy: 0.9595 CPU times: user 29.3 s, sys: 999 ms, total: 30.3 s Wall time: 23 sscore, acc = model.evaluate(x_test, y_test)
--------------------------------------------------------
Test score: 0.15089635097590393
Test accuracy: 0.9595129489898682The validation accuracy is 96.0%. The following graphs also visualise the training processing of the deep learning model.

Alright, so now the model is well trained and ready to be tested by testing data.
score, acc = model.evaluate(predict_data, target_data)
print('Test accuracy:', acc)
--------------------------------------------------------
Test accuracy: 0.8817499876022339The testing accuracy is 88%, indicating that the model is decent enough to classify the potential caravan customers. We will have a further investigation in the confusion matrix below.

Result
By applying the model on 4000 testing data, we can observe the model performance from the classification report and confusion matrix below.
Overall performance: 88% accuracy on testing data
The overall accuracy of the classification is 88%. However, overall accuracy is not the sole measure to evaluate the model performance since the accuracy can be easily achieved by simply classified all data as a negative result in this rare event classification. Therefore, we need to further consider the precision of both positive and negative prediction as well.
Identifying non-target users: 95% precision
As we expected, the model gives a good result in identifying the negative target (non-users) with 95% accuracy. However, this result does not help a lot to the caravan business since the objective should be identifying potential users. Therefore, we need to consider positive precision.
Identifying target users: 15% precision
This precision reflects how good is the model to identify positive result, i.e. the potential caravan users. Among 4000 testing data, the model predicts there are 347 potential users and the accuracy of identifying caravan users is 15%.
False positive rate: 7.6%
False-positive rate reflects the proportion of all negatives that still yield positive test outcomes. A higher false-positive rate means more data are incorrectly identified as potential users.
This is usually a measure indicating effectiveness when we need to apply marketing strategies to the target group. For instance, when we spend resources to promote caravan to those categorised as potential users according to this model, 7.6% of them would be wasted since they are not caravan customers.
So far we can construct a simple deep learning model with 3 hidden layers to identify potential customers with 88% accuracy. To improve the model, we can always try other combinations of the model setup or some suggests another deep learning - autoencoder, which divides the input into larger network and then re-construct the output with similar as the input. It is believed this can perform well to handle these rare event classifications.



Comments